The Great Gatsby
I opened up Project Gutenberg and started thinking of what I could select as my text of choice. I was thinking Frankenstein but I think I remember that being an example from the default options, so I wanted to pick something different. I read The Great Gatsby in highschool and it was available, so I chose it.
The first thing I did was copy and paste the text file. These were the initial results.

This sort of information needs to be cleaned up, there are words that are listed that probably shouldn’t be there. It is debatable whether something like “got” or “don’t” are semantically meaningful, but “I’m” and “said” feel like they really should not be included. The words “project” and “gutenburg” are also included as artifacts of the raw text file I downloaded, which obviously should not be included.
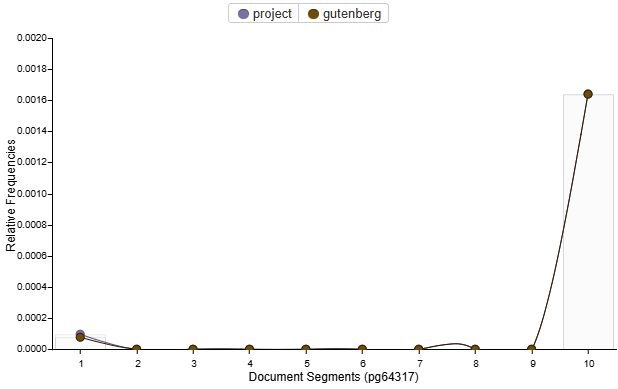
The usage of those two words in particular are all concentrated in the end, which is kind of funny. It makes sense since all of the information regarding this project (Project Gutenburg) would only really make sense before or after the text of the book.
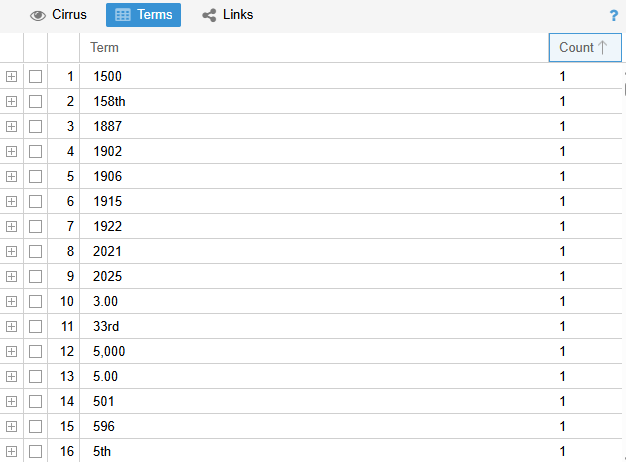
This chart of word frequency by least frequently occurring words is also interesting. Random numbers and if you scroll down (not shown here), a bunch of random words used only a single time in the whole novel. These are small so that they don’t hold much weight in the analysis, but worth keeping in mind of their existence.
Analytical Approach
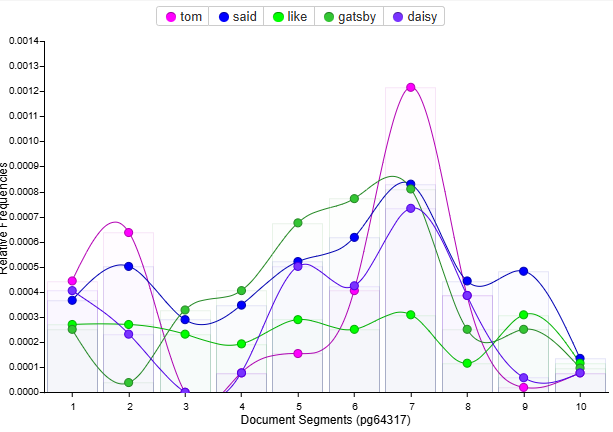
Relative frequency is a really powerful tool. If you could split everything into chapters instead of evenly spaced segments, relative frequency would work very good in maintaining data in various sample sizes. Exact word count in each chapter would mess up the data.
A piece of information I found really useful is the relative frequency of character names. They let you have a glance of the relative importance or frequency of their mentions over the course of the text.
Conclusion
With the increasing popularity and devlopment of these tools that analyze large works, there are a few things that I think should be kept in mind. Making sure no artifact text or random nonsense is included is very important, as it can skew the data. The user also needs to be very proficient with the program of choice, especially if they plan on publishing results. Having it peer reviewed would help a lot as well because the other party can find any crucial errors.
I think this is a great in-depth analysis. I like how you took the time to think about artifacts of the Project Gutenberg platform and not just the book itself. I’m curious if you found any interesting links between the characters’ names (since those were the most commonly occurring words) in the Cirrus tool – I feel like that could create some interesting connections about the plot. Great work!